El contenido duplicado se refiere al hecho de que exista más de una página con el mismo contenido, ya sea del mismo dominio o ajeno. O sea, que existan dos o más URL’s con el mismo texto.
Google, al advertirle esto, le quiere pedir de la manera más atenta que si usted publica contenido, éste sea único y original, que sea usted el autor y no se lo haya pirateado. (Justo hace unos días sucedió que cierto presidente fue acusado de plagiar su tesis, no queremos que se nos compare con él.)
Ahora, si estás preocupado por esto, probablemente está despertando en ti una inquietud por mejorar tu sitio web, optimizarlo, posicionarlo orgánicamente en Google, hacerle SEO pues; y al hacer un análisis alguien (alguna herramienta) te ha acusado de tener contenido duplicado.
¿Grave? R: Puede ser.
¿Pero por qué a Google le molestaría que tengas contenido que se tomó de otro sitio web?
Para ponerte en contexto, resulta que aproximadamente el 97% de las ganancias de Google se generan de los espacios publicitarios que vende en su buscador y su red de anunciantes. Google es quien domina el mercado del search, más del 90% de los usuarios de internet utilizan Google como motor de búsqueda, por ello todo el mundo invierte en Google para hacer paid search (Adwords).
Lo anterior hace a Google el líder en el mercado de las búsquedas, por consiguiente los anunciantes desean aparecer en este buscador cada que un usuario busca algo relacionado con sus productos o servicios.
La clave del negocio de Google es el Search Experience
Si Google es la herramienta de búsqueda que más se utiliza por los targets objetivos en cada uno de los mercados donde tiene presencia una marca, es bastante entendible que los anunciantes estén anciosos por tener participación en este buscador. Justo así nace la demanda que permite el desarrollo y la participación de la mayoría de los productos de Google.
Y bueno, alguno de ustedes podrán decir que tiene un tío que usa siempre Yahoo o Bing y tendrá razón, pero los searchers frecuentes (que somos más) sabrán que hay algo que distingue las búsquedas realizadas en Google contra las de otros buscadores, me refiero a la experiencia de búsqueda; el hecho de que cuando uno busca en Google encuentra lo que necesita.
Aquí es justamente cuando diferenciamos entre tráfico pagado y orgánico, pero hacía falta asomar el modelo de negocio de Google para terminar de comprender su interés por la calidad, funcionalidad y autenticidad del contenido.
Si bien las políticas de los anuncios de texto de Google piden claridad y relevancia, con los resultados orgánicos la exigencia es mayor, pues para Google resulta ese su diferenciador como producto; la experiencia de encontrar lo que buscas. Uno no paga por una posición orgánica, Google arroja lo que su algoritmo cree que es más relevante para el usuario, incluso tiene un algoritmo dedicado a entender mejor las consultas del usuario para poder llevarlo a un nivel conversacional y más intuitivo.
El mencionado algoritmo, Hummingbird, se asemeja cada vez más a la inteligencia artificial y está en constante mejora. Quizá pronto alcancemos un nivel conversacional y de inteligencia artificial similar al de la súper computadora Watson.
Y hablando de algoritmos, justo Google tiene otro animalito que se encarga de penalizar malas prácticas como el contenido duplicado, que es Panda. Vale la pena hacer un post compeltito para cada uno de los anteriores algoritmos, pero mientras te adelanto que Panda es el que penalizará las malas prácticas de tu contenido, así que aguas. 😉
Con todo esto entendemos que la autenticidad y originalidad del contenido se vuelve un valor añadido; importa y mucho.

Bueno, ya más acción y menos bla, bla
Volviendo al problema técnico, existen algunos casos en los que algunas herramientas dicen que tenemos contenido duplicado, aun cuando nuestro contenido es único y esto se debe no precisamente a que alguien se haya volado (robado) nuestro contenido, pues Google verifica quién lo ha publicado primero, es más bien un problema de generación dinámica de URL’s.
Para empezar, algunas de las herramientas gratuitas que les recomiendo para analizar si el contenido de su sitio web está duplicado son:
Siteliner
Esta herramienta en su versión gratuita te permite analizar qué tanto contenido duplicado tienes en tu sitio web y dónde está localizado.
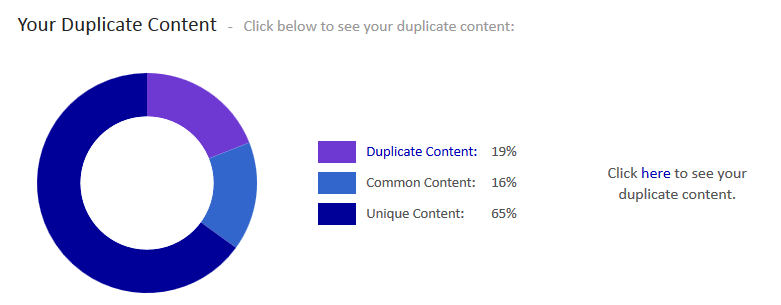
Una vez que damos clic para ver el contenido duplicado, podemos observar un listado de las páginas que contienen contenido duplicado y el número de palabras que la herramienta detecta como duplicadas.
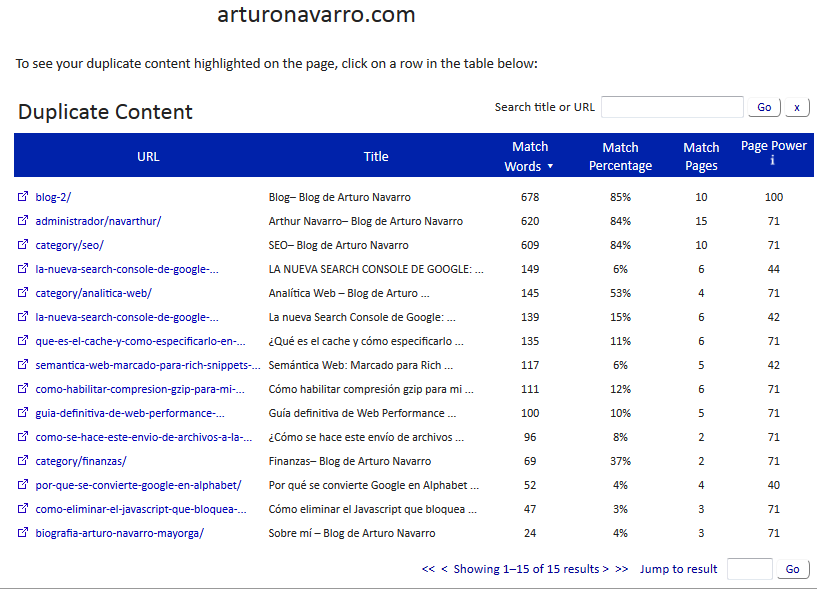
Una vez hecho esto, podemos dar clic en cualquiera de las opciones y ver con qué páginas compartimos contenido, según esta herramienta.
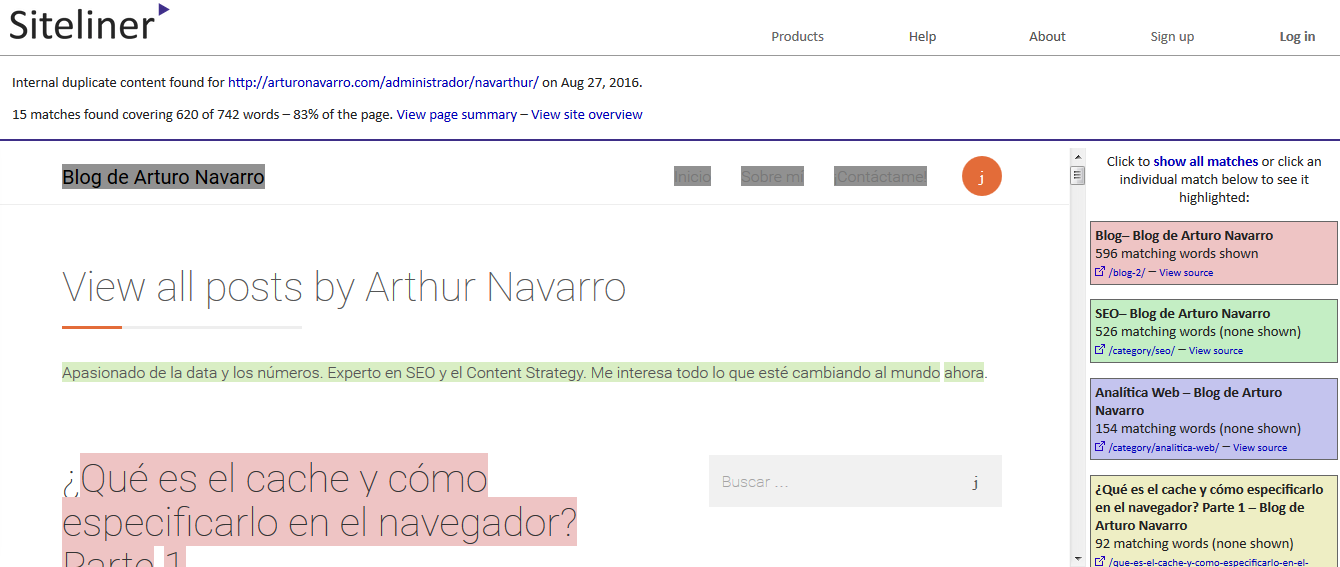
Como podemos ver, en realidad no es que mi blog tenga páginas distintas con el mismo contenido, pero sí se imprime mi contenido con diferentes URL’s. Esto también es un tema de categorías, la herramienta está detectando que se imprime una URL de mi Home por cada categoría (SEO, Analítica Web, etc.).
Screaming Frog
Otra herramienta u forma de verlo es con Screaming Frog, de la cual también puedes usar la versión gratuita, la cual te analiza hasta 500 URLs.
Pues con esta herramienta, al analizar tu dominio te soltará todas las URLs que detecta, entre las cuales verás varias versiones de la misma página. Cuando ocupamos CMSs suele pasar, y más sí se trata de un ecommerce.
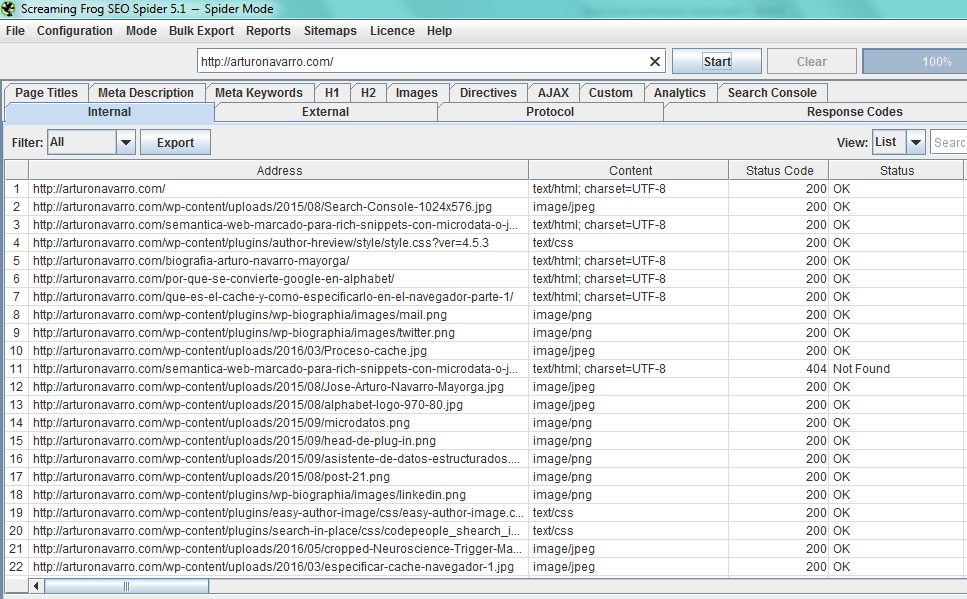
Muchas veces pasa que tenemos un Home y asumimos que éste deberá ser el Index de nuestro sitio web, sin embargo, no precisamente resulta así. Aquellos desarrolladores web de la vieja escuela deberán recordar, cuando no era tan usual utilizar WordPress (dado que ahora se ha vuelto prácticamente un Framework), que el primer archivo, el que solíamos definir como Home del sitio web y que tenía el nivel superior de navegación, siempre era nuestro Index. Algunos sitios raros desarrollados a mano aún suelen cometer éste error. Suelen imprimir 2 URL’s distintas para el Home:
www.misitio.com/
www.misitio.com/index
Ante el servidor sólo existía un archivo, pues era nuestro Home o Index, pero ante un cliente (navegador) existían 2.
Otro ejemplo es cuando tenemos un ecommerce. Pongo un ejemplo de Foo.com.mx
Si se dan cuenta el path para llegar a este producto es:
Home> Camisetas > Camiseta desteñida manga corta
Se puede observar en la URL: http://foo.com.mx/camisetas/1-camiseta-destenida-manga-corta.html
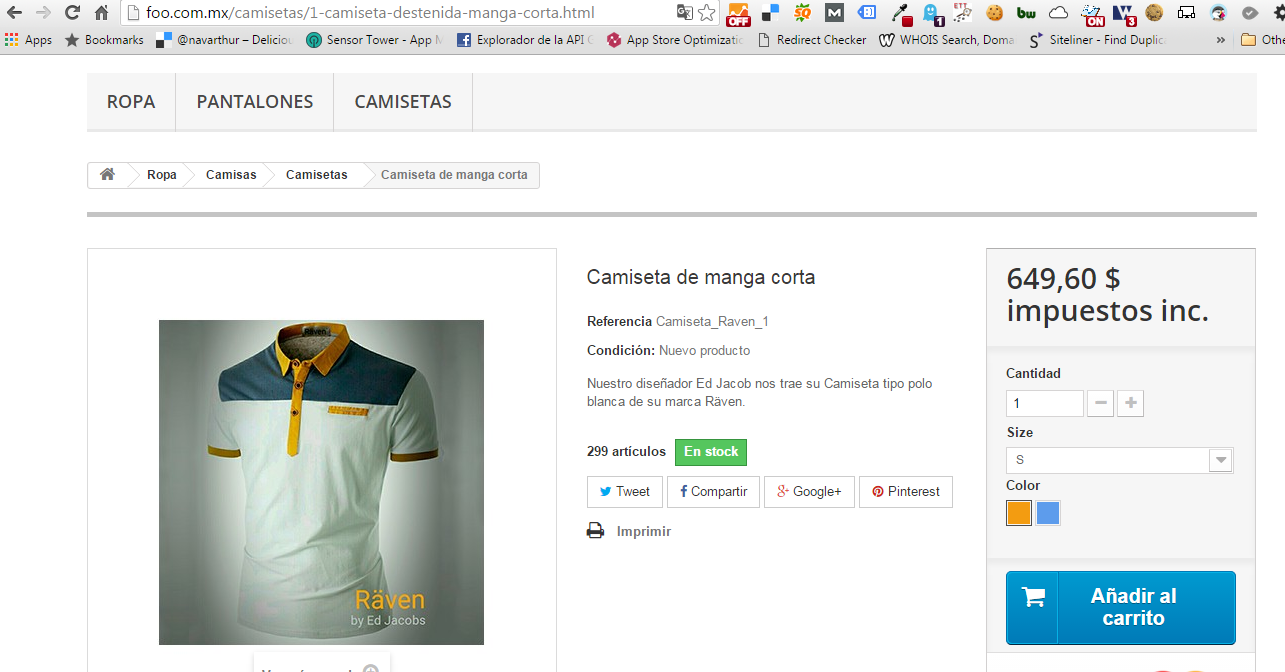
Pero, qué pasa cuando hay más de una manera de llegar al mismo producto, otro path.
Digamos que este producto entra dentro de alguna nueva categoría que se llama: Lo más nuevo.
El path cambiaría, pues ahora sería:
Home> Lo más nuevo > Camiseta desteñida manga corta
Y nuestra URL cambiaría a algo así:
http://foo.com.mx/lo-más-nuevo/1-camiseta-destenida-manga-corta.html
Entonces, si se dan cuenta, ya tenemos 2 URLs distintas del mismo contenido y aunque en nuestro servidor esto sigue siendo el mismo archivo (o los mismos archivos, ya que actualmente los CMS componen una página de diferentes archivos) para Google o cualquier buscador, es más para cualquier navegador o robot (en resumen cualquier cliente) son 2 páginas distintas.
¿Cómo soluciono el contenido duplicado?
Porque ya saben que nunca escribo sobre algo sin proponer una solución, les contaré qué hago yo.
Si de plano, alguna de estas herramientas les indica que efectivamente alguna página está duplicada, que realmente tengan el mismo contenido 2 veces, quizá porque en el WordPress hicieron un borrador y luego se les olvidó, pues en ese caso es muy simple: elimínenlo. Eso puede pasar y lo que hace, por ejemplo WordPress, es generar la versión 2 del contenido. Ejemplo:
www.misitio.com/mis-servicios
www.misitio.com/mis-servicios-2
En ese caso, y si la segunda URL ya está indexada, lo único que deberán hacer es eliminarla y aplicarle un redireccionamiento 301 de esta segunda URL a la primera. ¿Cómo saber si ya está indexada? Vayan a Google y utilicen el comando inurl:www.misitio.com/ mis-servicios-2.
En el segundo caso, que es muy claro que sucede con frecuencia, pues les recomiendo que utilicen una alternativa que ofrece Google, de hecho no sólo es de Google, la idea fue presentada por Yahoo! y Bing en conjunto con Google en el 2009. Se trata de asignar una página canónica con la etiqueta “canonical”.
Tal cual es, si por ejemplo tenemos estás URLs generadas automáticamente para el mismo contenido:
www.misitio.com/categoría1/producto1
www.misitio.com/categoría2/producto1
misitio.com/categoría1/producto1
En este caso, suponemos que el path canónico, el que queremos asignar como principal ante Google es:
Home > Categoría 1 > Producto 1
Entonces en el Head de ambas páginas deberás agregar la siguiente etiqueta HTML:
Esto le dirá a Google, y demás buscadores, que esa es la ruta principal, y que las demás son versiones de la misma. Con eso bastará para que no se considere contenido duplicado.
Y bueno, aunque este video es del 2014, al día en que se escribe este artículo es vigente. Nota importante, en temas digitales, siempre que revisen un blog revisen la fecha de publicación, quizá lo que se escribe hoy, mañana ya no sea vigente. Por lo menos en este blog, les prometo que si algún post caduca, lo actualizaré.
Les dejo al viejo Matt.
Te invito a seguirme en Twitter y por favor vota por el contenido:
[yasr_visitor_votes]