Google es cada día más semántico y más intuitivo. Cada actualización de panda y hummingbird está destinada a entender mejor la manera en que los contenidos están clasificados y cómo los usuarios realizan sus búsquedas. Se utilizan técnicas de lenguaje natural, así es, las mismas con las que se trabaja para la inteligencia artificial.
Aun cuando los avances de lectura e interpretación de los robots de Google han sido impresionantes últimamente, siempre hay formas de darle una ayudadita para entender mejor el contenido de nuestra web. Ya lo hacemos con los metadatos, como con el title e incluso con metadatos en el body, como las etiquetas Alt que es uno de los principales indicadores para los robots de Google sobre qué es lo que aparece en la imagen. Para entender el método completo que utiliza Google para clasificar imágenes con su algoritmo de reconocimeito próximamente presentaré el post, Indexa imágenes entendiendo Google Images.
Entonces, la manera de poder indicarle a Google en qué consisten el resto de los elementos de nuestra web es marcándolos. Googlebot puede ver números, pero quizá no saber que se trata de un teléfono de contacto, no entender que una imagen es el logo de nuestra empresa o no saber que un review de un cliente satisfecho es más que sólo un fragmento de texto.
 Algunas ventajas de este tipo de marcado según, W3C, Wikipedia y el sitio oficial www.rdfa.info serían:
Algunas ventajas de este tipo de marcado según, W3C, Wikipedia y el sitio oficial www.rdfa.info serían:
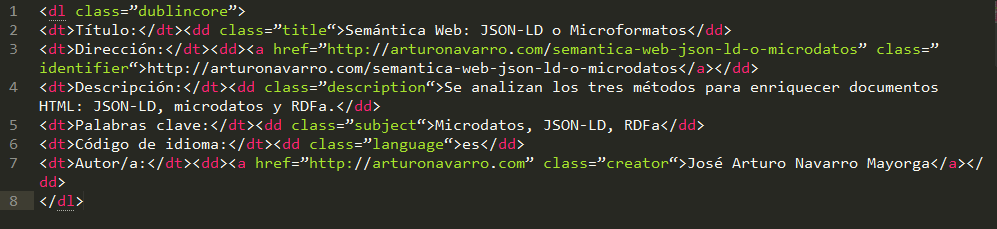 Dublin Core, como pueden ver en la clase inicial, es un pequeño set de vocabulario que se utiliza para recursos web como videos, imágenes y páginas web. No se utilizaba schema.org con los microformatos.
Los microdatos son una respuesta a los RDF’a a partir del HTML5 y trabaja agrupando ítems con propiedades nombre-valor, menos engorroso que los microformatos. Utilizan el atributo itemscope dentro de un div para marcar un paquete de datos y luego se describen con el atributo itemprop, lo mejor de este formato fue que comenzó a utilizarse ya con schema.org a diferencia de los microformatos y su Dublin Core.
EL formato de microdatos se ve de la siguiente manera:
Dublin Core, como pueden ver en la clase inicial, es un pequeño set de vocabulario que se utiliza para recursos web como videos, imágenes y páginas web. No se utilizaba schema.org con los microformatos.
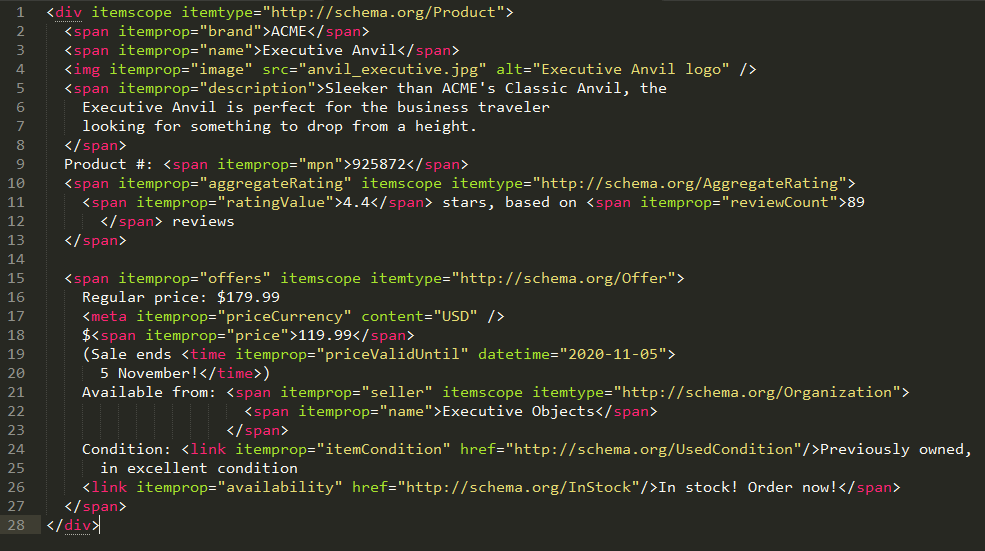
Los microdatos son una respuesta a los RDF’a a partir del HTML5 y trabaja agrupando ítems con propiedades nombre-valor, menos engorroso que los microformatos. Utilizan el atributo itemscope dentro de un div para marcar un paquete de datos y luego se describen con el atributo itemprop, lo mejor de este formato fue que comenzó a utilizarse ya con schema.org a diferencia de los microformatos y su Dublin Core.
EL formato de microdatos se ve de la siguiente manera:

 Aquí vemos los diferentes ítems que Google nos permite marcar, por ahora, tanto en un sitio web como en un correo electrónico, así es también se pueden marcar correos electrónicos para generar snippets bastante interesantes, pues Gmail puede mostrar rich snippets como el siguiente:
Aquí vemos los diferentes ítems que Google nos permite marcar, por ahora, tanto en un sitio web como en un correo electrónico, así es también se pueden marcar correos electrónicos para generar snippets bastante interesantes, pues Gmail puede mostrar rich snippets como el siguiente:
 Bueno, ya una vez habiendo elegido, en este caso sitio web se coloca la url que se desea etiquetar y se agregan los campos requeridos, dependiendo el tipo de etiquetado que se haya elegido, en este caso fue por artículo.
Bueno, ya una vez habiendo elegido, en este caso sitio web se coloca la url que se desea etiquetar y se agregan los campos requeridos, dependiendo el tipo de etiquetado que se haya elegido, en este caso fue por artículo.
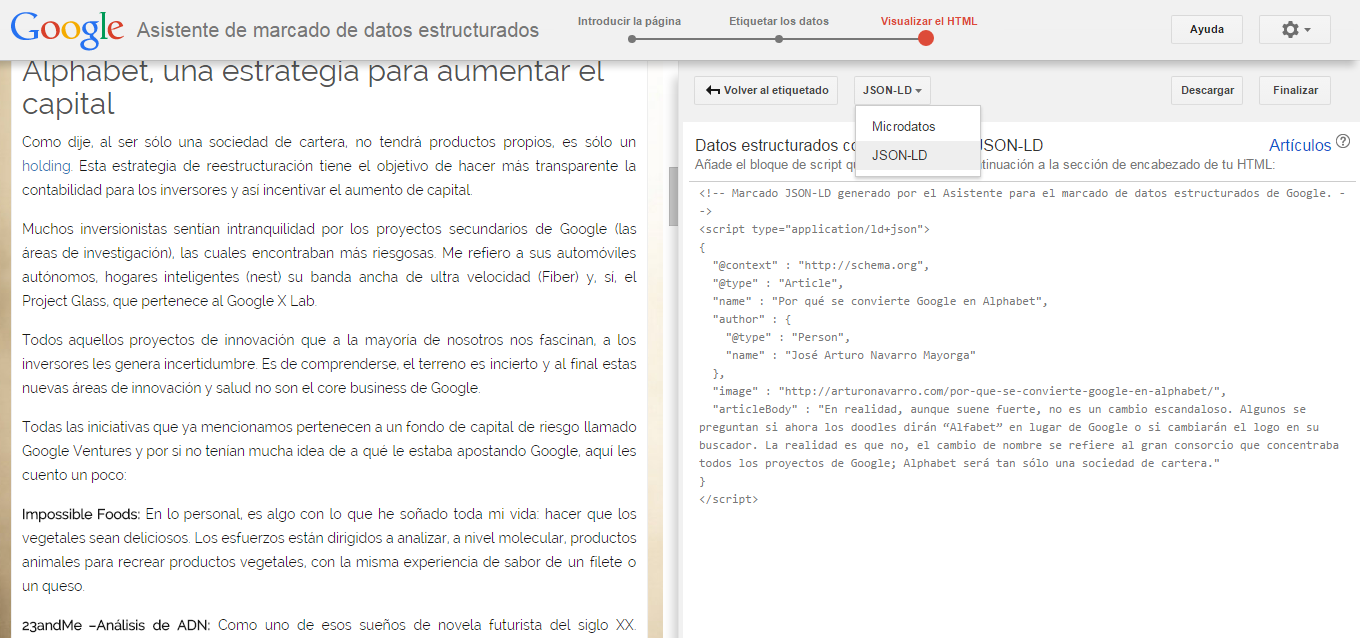
 Una vez esto hecho, da clic en el botón de Crear HTML y lugeo eliges JSON-LD o microdatos si prefieres, y te generará el código que deberás pegar en el head de tu sitio.
Una vez esto hecho, da clic en el botón de Crear HTML y lugeo eliges JSON-LD o microdatos si prefieres, y te generará el código que deberás pegar en el head de tu sitio.
 Si usas un wordpress, existen varios plug ins para insertar scripts en el head de tus páginas e incluso algunos para microdatos y JSON-LD directamente, aunque no con muy buenos resultados hasta el momento. Recomiendo ampliamente generarlo manual, mientras JSON-LD permite que se generen plug ins con buenos resultados.
Para lo anterior les recomiendo el siguiente plug in, a mí me ha funcionado bien:
https://es.wordpress.org/plugins/addfunc-head-footer-code/
Si usas un wordpress, existen varios plug ins para insertar scripts en el head de tus páginas e incluso algunos para microdatos y JSON-LD directamente, aunque no con muy buenos resultados hasta el momento. Recomiendo ampliamente generarlo manual, mientras JSON-LD permite que se generen plug ins con buenos resultados.
Para lo anterior les recomiendo el siguiente plug in, a mí me ha funcionado bien:
https://es.wordpress.org/plugins/addfunc-head-footer-code/
 El cual les generará un box como el siguiente:
El cual les generará un box como el siguiente:
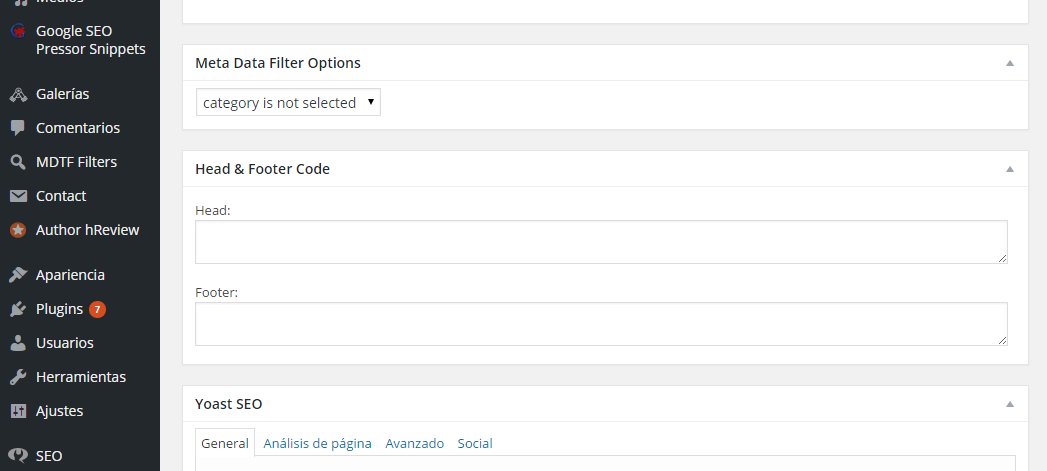 ¡Ingresen ahí el código de JSON-LD que generaron en el Asistente de marcado de datos estructurados y listo!
¿Dudas? Un correíto y les contestaré ASAP. Hasta el siguiente post.
[yasr_overall_rating size=”medium”]
“Recuerden, nadie sabe todo, hasta cierto punto, porque siempre hay excepciones. ¡Eso es probabilidad!”
Te invito a calificar este artículo y a seguirme en Twitter.
[yasr_visitor_votes]
Follow @JarthurNavarro
¡Ingresen ahí el código de JSON-LD que generaron en el Asistente de marcado de datos estructurados y listo!
¿Dudas? Un correíto y les contestaré ASAP. Hasta el siguiente post.
[yasr_overall_rating size=”medium”]
“Recuerden, nadie sabe todo, hasta cierto punto, porque siempre hay excepciones. ¡Eso es probabilidad!”
Te invito a calificar este artículo y a seguirme en Twitter.
[yasr_visitor_votes]
Follow @JarthurNavarro
Todos podemos marcar elementos en nuestra web
Si por ejemplo en nuestro sitio almacenara información sobre una película o un álbum, Google no distinguiría al director de la película, al guionista o al reparto, igualmente con el álbum musical, no distinguiría el campo de productor o nombre de la banda. Para eso existe el marcado, con ello podemos indicar que una cadena de texto es un autor o el director de una película; saber que una serie de números es un teléfono de contacto o un precio, quizá una oferta e incluso cuál es el producto. Uno de los aspectos más interesantes del marcado es que esto permite que Google muestre algo llamado Fragmentos Enriquecidos, “Rich Snippets”, que son elementos que enriquecen los snippets de Google en lugar o además de nuestra description.Qué es schema.org y por qué es indispensable para Google
El lenguaje estructurado es un proyecto que se ha utilizado para XML desde el siglo pasado, donde se ha tratado plantear distintos tipos de estructura, con el objetivo de crear normas que estandaricen la forma de marcado de los documentos XML. (Para profundizar en semántica web, pronto publicaré un artículo sobre qué es el XML, su diferencia y relación con el HTML y el SGML). Bueno, para fines de este artículo nos interesa la iniciativa schema.org, que es un proyecto en el que trabajaron y estandarizaron en conjunto Google, Bing y Yahoo, los principales motores de búsqueda del mundo (para quienes vayan a saltar preguntando ¿y Baidu?, quizá, repito, quizá, después hablemos de él, pero ahora también reconoce el marcado de schema.org). El 2 de junio del 2011 Google, Bing y Yahoo estandarizaron un esquema de marcado web a manera de normatividad (Yandex, el motor ruso se unió a la iniciativa en noviembre del mismo año). En esa iniciativa se presentó el vocabulario schema.org, el que se propuso utilizar con los formatos Microdata, RDFa, or JSON-LD. Por cierto, les recomiendo leer el blog oficial de schema: http://blog.schema.org/ Ya con este consenso, se volvió más sencillo para los webmasters etiquetar sus webs. El vocabulario es schema.org sin importar el motor de búsqueda con el que quisieran comunicarse, ahora sólo había que elegir qué formato se utilizaría para hacer el marcado, cuestión que es vigente y que sigue siendo un tema a discutir durante el etiquetado de una web. Vale la pena mencionar que existe más de un vocabulario, como data-vocabulary.org, pero Google recomienda ampliamente utilizar schema.org.RDFa
Mencionamos a RDFa a manera de investigación, aunque la recomendación es elegir entre Microdatos y JSON-LD. Este concepto nace del RDF (Resource Description Framework) que es una familia de especificaciones de la W3C (World Wide Web Consortium), la asociación internacional que emite recomendaciones y normatividades para la World Wide Web. Originalmente diseñado como un modelo de datos para metadatos, sólo se le agregó la “a” de “attributes”. Son un conjunto de extensiones de XHTML propuestas por W3C. Hace algún tiempo, cuando aún existían aún los microformatos (antes de los microdatos), sonaba ser una propuesta muy innovadora por todas las herramientas para hacer cosas con RDF, como tiendas, los motores de búsqueda, lenguajes de consulta y gráfico visualizadores. El objetivo, así como los demás formatos, es introducir semántica para los documentos. Una de sus principales características es que aprovecha atributos de los elementos meta y link de XHTML y los generaliza de forma que puedan ser utilizados en otros elementos. Este formato utiliza los siguientes atributos:- typeof: indica de que tipo es la instancia descrita.
- about: una URI que indica el recurso que describen los metadatos y que remite al documento actual por defecto.
- rel, rev, href y resource: atributos que establecen un relación o relación inversa con otro recurso.
- property: aporta una propiedad para el contenido de un elemento
- content: atributo opcional que se sobrepone al contenido del elemento cuando se usa el atributo property.
- datatype: atributo opcional que indica el tipo de datos del contenido.
Algunas ventajas de este tipo de marcado según, W3C, Wikipedia y el sitio oficial www.rdfa.info serían:
- Independencia del editor: cada sede web puede usar sus propios estándares.
- Reutilización de datos: se debe tratar de no duplicar los datos; RDFa hace innecesario separar las secciones XML y HTML de los mismos contenidos.
- Autocontención: las secciones de XML y HTML pueden mantenerse separadas.
- Modularidad del esquema: Los atributos son reusables
- Escalabilidad: se pueden añadir campos adicionales con la única condición de que se mantenga la capacidad de extraer semántica de los datos del archivo XHTML.
Microdatos: Por cierto, no son sinónimo de microformatos
Es el formato más popular y más utilizado actualmente para etiquetar los elementos de una web. La finalidad sigue siendo obtener una mayor semántica y esos llamativos Rich Snippets, que son bastante buenos para aumentar los CTR’s orgánicos. Como mencionamos anteriormente, antes de los microdatos existía otro formato llamado microformatos, es importante no confundirlos, ya que suele existir esta confusión e incluso en muchos artículos en la web andan por ahí mencionando microformatos cuando se refieren a los microdatos. Los microformatos estaban basados en porciones de código HTML o XHTML, estos permitían estructurar la información aprovechando los atributos “id” o “class” del código. Así se ve un etiquetado con microformatos:
Dublin Core, como pueden ver en la clase inicial, es un pequeño set de vocabulario que se utiliza para recursos web como videos, imágenes y páginas web. No se utilizaba schema.org con los microformatos.
Los microdatos son una respuesta a los RDF’a a partir del HTML5 y trabaja agrupando ítems con propiedades nombre-valor, menos engorroso que los microformatos. Utilizan el atributo itemscope dentro de un div para marcar un paquete de datos y luego se describen con el atributo itemprop, lo mejor de este formato fue que comenzó a utilizarse ya con schema.org a diferencia de los microformatos y su Dublin Core.
EL formato de microdatos se ve de la siguiente manera:
JSON-LD
Como siempre, lo mejor para el final. JSON LD significa JavaScript Object Notation for Linked Data. Con este método se utilizan objetos JSON como estándar para la comunicación entre webs y schema.org. La ventaja principal de este método es que separa por completo la marcación de los elementos de del body y esto facilita el etiquetado para los desarrolladores, sobre todo para sitios que son muy dinámicos y van construyendo sus elementos con base en la interacción del usuario, como un ecommerce con carritos, check out’s y sugerencias de productos emergentes, quizá con Ajax. Utilizar JSON-LD permite implementar menos código y resulta más amigable tanto para robots como para desarrolladores. Basta con meter las especificaciones en el <head>, lo cual permite también que los robots no tengan que procesar todo el código HTML para entender las relaciones en el documento, sino que lo obtendrán directo de un objeto JSON. La sintaxis de JSON-LD es muy parecida a la de JSON, sólo se diferencia del uso de la @ para definir el contexto, que deberá ser schema.org y el tipo de contenido, @type que será nuestra web.
¡Comencemos a etiquetar con el Asistente de marcado de datos esturcturados!
Muchas veces tememos comenzar con el etiquetado, pero vamos a hacer uso de una excelente herramienta que nos regala Google para hacer más sencillo este procedimiento y asegurarnos de su correcta implementación: el Asistente de marcado de datos estructurados. Lo primero es ingresar a la Search Console y elegir el sitio que pretendemos marcar. Después nos dirigimos a otros recursos.
Aquí vemos los diferentes ítems que Google nos permite marcar, por ahora, tanto en un sitio web como en un correo electrónico, así es también se pueden marcar correos electrónicos para generar snippets bastante interesantes, pues Gmail puede mostrar rich snippets como el siguiente:
Bueno, ya una vez habiendo elegido, en este caso sitio web se coloca la url que se desea etiquetar y se agregan los campos requeridos, dependiendo el tipo de etiquetado que se haya elegido, en este caso fue por artículo.
Una vez esto hecho, da clic en el botón de Crear HTML y lugeo eliges JSON-LD o microdatos si prefieres, y te generará el código que deberás pegar en el head de tu sitio.
Si usas un wordpress, existen varios plug ins para insertar scripts en el head de tus páginas e incluso algunos para microdatos y JSON-LD directamente, aunque no con muy buenos resultados hasta el momento. Recomiendo ampliamente generarlo manual, mientras JSON-LD permite que se generen plug ins con buenos resultados.
Para lo anterior les recomiendo el siguiente plug in, a mí me ha funcionado bien:
https://es.wordpress.org/plugins/addfunc-head-footer-code/
El cual les generará un box como el siguiente:
¡Ingresen ahí el código de JSON-LD que generaron en el Asistente de marcado de datos estructurados y listo!
¿Dudas? Un correíto y les contestaré ASAP. Hasta el siguiente post.
[yasr_overall_rating size=”medium”]
“Recuerden, nadie sabe todo, hasta cierto punto, porque siempre hay excepciones. ¡Eso es probabilidad!”
Te invito a calificar este artículo y a seguirme en Twitter.
[yasr_visitor_votes]
Follow @JarthurNavarro